Key Moments
AI Dev 26 x SF | Aditi Gupta: Building SRE Agents with the Redis Context Engine
Want to know something specific about what's covered?
We've already dissected every moment. Ask and we will deliver (with timestamps).
Key Moments
SRE agents are now trustworthy and capable of real-time decision-making, but they cost $1M to build and require extensive, specialized infrastructure management.
Key Insights
An SRE agent was built and deployed in production for top-five financial institutions, demonstrating its scalability and reliability.
The naive approach to chunking with fixed character limits can lead to missing crucial information or dominant documents skewing results; the agent uses document-type specific strategies like keeping CLI/API docs whole.
A multi-agent architecture uses three specialized agents (knowledge, chat, deep triage) routed by a query classifier, rather than a single, monolithic agent, to prevent hallucinations.
Semantic caching, implemented with Redis, can make knowledge queries up to 15 times faster and 98% cheaper by serving previously answered questions without LLM calls.
Context window limitations in LLMs, such as 'loss in the middle' and 'recency bias,' manifest even before full capacity is reached, necessitating output compression and contextual caching.
The Redis Agent Memory Server provides both short-term (session) and long-term (persistent) memory, extracting key information like user preferences and environment facts using a nano LLM.
The complexity of modern infrastructure and the need for fast, accurate SRE support
The presentation highlights the immense complexity of modern IT infrastructure, where a single Redis service can comprise dozens of clusters across multiple regions, with hundreds of instances each having unique configurations and operational histories. This complexity makes it challenging for Site Reliability Engineers (SREs) to quickly diagnose and resolve issues. Traditional approaches struggle to keep pace, leading to high Mean Time To Resolution (MTTR) and potential service downtime. Aditi Gupta's team at Redis aimed to build a trustworthy SRE agent capable of operating effectively in such production environments, addressing the critical need for fast, context-aware, and evidence-driven answers.
Why LLMs alone are insufficient for production SRE tasks
While Large Language Models (LLMs) are rapidly advancing with larger context windows and improved reasoning capabilities, relying solely on them for SRE tasks presents significant challenges. The primary issue is the LLM's training data, which quickly becomes outdated, especially with the fast pace of software development and documentation changes. Attempting to circumvent this with web searches introduces unfiltered, potentially irrelevant, or erroneous information from community forums and outdated posts. LLMs can confidently present this incorrect information, leading to disastrous recommendations for critical infrastructure changes. This underscores the need for a specialized agent grounded in trusted, up-to-date, and relevant data sources.
Designing for trust: Grounded, context-aware, evidence-driven, and verifiable agents
The foundational goal for the SRE agent was 'trustworthiness,' which guided every architectural decision. This translates into several key principles: the agent must be grounded in authoritative sources, context-aware of specific deployments, evidence-driven by live operational data, and verifiable, meaning it must cite its sources. By adhering to these principles, the agent aims to meet SRE KPIs such as minimizing MTTR and maximizing service uptime. The knowledge base for this agent is built on official Redis documentation across various deployment types (open-source, Redis Cloud, Redis Enterprise), ensuring data quality and relevance. This information is chunked, embedded, and stored in Redis, leveraging it as a vector library for semantic search, which allows for conceptually relevant retrieval and metadata filtering, all performed at Redis's characteristic in-memory speed.
Strategic chunking for optimized retrieval and context management
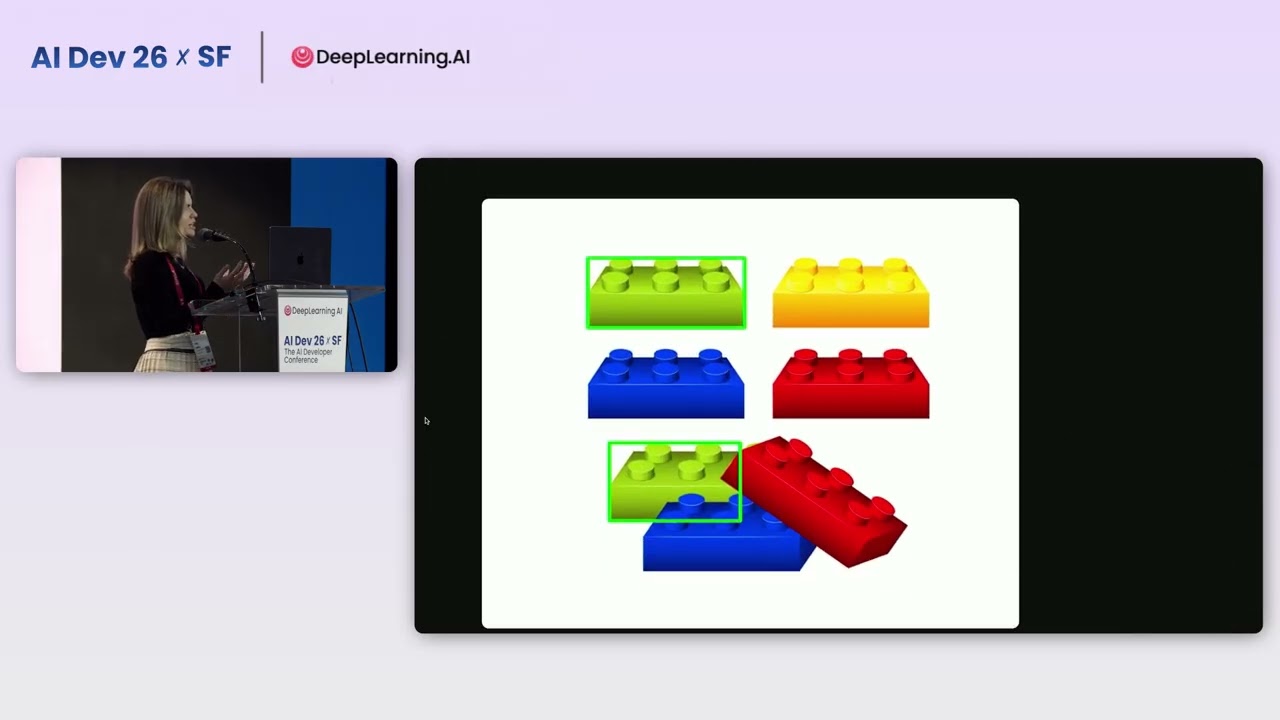
The process of chunking, breaking down large texts into smaller pieces for LLMs, is critical and requires strategic consideration beyond naive fixed-size splits. A naive approach, such as chunking every 50 characters, can result in fragmented commands or parameters, leading to incomplete information. Conversely, very large documents can dominate retrieval results. The developed strategy tailors chunking to document types: CLI and API documentation are kept whole to preserve command integrity, while extremely long documents have chunk limits set to prevent overrepresentation. Metadata like YAML front matter is stripped to avoid polluting vector searches. This meticulous approach to chunking ensures that retrieval is safer, more accurate, and protects against potential LLM hallucinations.
A multi-agent architecture for specialized tasks and reduced hallucinations
Instead of a single agent attempting all tasks, a multi-agent architecture was implemented featuring three specialized agents: a Knowledge Agent for documentation queries, a Chat Agent for general triage and diagnostics with full tool access, and a Deep Triage Agent for exhaustive investigations using MapReduce. A query router classifies incoming requests and dispatches them to the appropriate agent, significantly reducing hallucinations and improving efficiency. The Deep Triage Agent breaks down complex incidents into topics, ranks them by severity, and assigns parallel workers for research, with an orchestrator consolidating findings. A crucial 'fact corrector' pass reviews the final output, using the knowledge base to remove unsafe or fabricated commands, serving as a final defense against errors.
Optimizing LLM usage with tailored model sizes and semantic caching
The strategy for model selection involves matching task complexity to LLM capability, rather than defaulting to the largest model. For heavy reasoning or final recommendations, a large model is used. However, for tasks like per-topic research in deep triage or general knowledge tasks, a smaller, faster 'mini' model is employed to manage costs and latency, especially when dealing with dozens of potential model calls in a single investigation. This 'mini' model also handles classification tasks for the agent router. Furthermore, semantic caching, powered by Redis, significantly enhances efficiency by storing and retrieving answers to recurring knowledge queries. When a new query is semantically similar to a cached one (above a certain threshold), the cached answer is returned without an LLM call, reportedly making these operations up to 15 times faster and 98% cheaper. This strategy is best suited for predictable query patterns, not dynamic tool outputs.
Addressing LLM context window limitations and managing tool outputs
The presentation addresses the well-known limitations of LLM context windows, such as the 'loss in the middle' problem (models ignoring mid-context information) and 'recency bias' (overweighting recent information). These issues emerge well before the window is full, often around the halfway mark. To combat this, especially with large tool outputs like thousands of tokens of logs, strategies include compressing large outputs to a standard summary (e.g., 500 tokens) and storing the full output in Redis. An 'expand context' tool allows the LLM to retrieve the full output if needed. Tool results are also cached per session, so if the same tool is called multiple times within a session with identical parameters, subsequent calls return immediately, preventing repeated token usage and latency, particularly beneficial for parallel processes in deep triage.
Integrating diverse knowledge sources and enabling personalized agent behavior
The agent integrates various knowledge sources beyond official documentation. 'Skills' are operational runbooks ingested as first-class documents and retrieved automatically. 'Pinned policies' ensure that critical organizational rules are always passed to the agent in system context, regardless of the query. Support tickets are ingested to leverage past resolutions for diagnosing new issues. Notably, the system supports hybrid search within Redis, combining exact text matches with semantic search to handle complex queries that require finding specific tickets (e.g., INC12345) and semantically similar incidents simultaneously. This hybrid approach ensures comprehensive information retrieval.
Memory management for persistent learning and personalized interactions
The Redis Agent Memory Server provides a sophisticated memory system for the agent. It stores both short-term (session) memory and long-term, ephemeral memory that persists across sessions. Messages and tool call results are stored in Redis. Regularly, an extraction pipeline graduates messages into longer-term memory using a nano LLM and custom extraction strategies. This process identifies user preferences, recurring incidents, and environmental facts, along with topics and named entities. This distilled information is stored, not just raw session data, to optimize storage costs and context window usage. When a query comes in, the agent can leverage this memory to retrieve relevant past information, enabling personalized interactions, such as the user's preference for succinct answers or the need for extensive command details, surfacing this context from the get-go.
Verifiability and proactive operations through citations and scheduling
Crucially, for SREs to trust the agent's recommendations, 'the agent said so' is insufficient. Every agent output includes citations to the accessed documents and tool calls, allowing on-call engineers to verify the recommendations themselves. This transparency is vital for auditing and empowering engineers to make the final decision. Furthermore, the agent can operate on a schedule, shifting from a reactive to a proactive stance. It can monitor infrastructure, run automated diagnostics, and generate daily or weekly health summaries. This scheduled, proactive operation allows the agent to alert users to potential issues before they even think to ask, significantly enhancing operational efficiency and preventing incidents.
Redis as a foundational context engine for a unified agent ecosystem
The presentation concludes by emphasizing Redis's role not just as a cache, but as a comprehensive 'context engine' for the SRE agent. It leverages Redis for its semantic vector store capabilities, acts as a thread manager, enables hybrid search, stores schedules for proactive functions, serves as a semantic cache, holds partner-added tribal knowledge, functions as the memory server, and catalogs infrastructure resources. This unified approach, enabled by Redis's diverse features, results in an agent that is grounded, context-aware, evidence-driven, and verifiable, making it a powerful tool for modern SRE operations.
Mentioned in This Episode
●Products
●Software & Apps
●Companies
●Organizations
●Concepts
Agent Performance Gains with Semantic Caching
Data extracted from this episode
| Feature | Improvement Factor | Cost Reduction |
|---|---|---|
| Semantic Cache | 15x faster | 98% cheaper |
Common Questions
The agent addresses the complexity of large-scale Redis deployments, where managing numerous clusters, regions, instances, and configurations becomes challenging. It aims to provide fast, accurate, and context-aware answers to SREs when issues arise, reducing Mean Time To Resolution (MTTR).
Topics
Mentioned in this video
Large Language Models, discussed in terms of their increasing capabilities but also limitations regarding outdated data, unfiltered web search, and potential for hallucinations when used without proper grounding.
A data serialization language, mentioned in the context of stripping YAML front matter from markdown files to prevent it from polluting vector similarity searches.
A collaboration software used for documentation, mentioned as a place where organizational knowledge might reside but go unread.
The company behind the Redis context engine and database, discussed as a core technology for building SRE agents, vector libraries, caching, and memory servers.
A component created by the Applied AI team at Redis to manage memory within an agent, storing messages and tool call results for both short-term (session) and long-term (ephemeral) persistence.
A programming model for processing large data sets in parallel, used in the deep triage agent for exhaustive investigation by breaking down queries into smaller topics.
Retrieval Rank Fusion, a technique used in hybrid search to combine results from different search mechanisms for more complex queries.
An agent designed for Site Reliability Engineering tasks, focused on providing trustworthy, context-aware, and verifiable recommendations for managing complex infrastructure.
More from DeepLearningAI
View all 80 summaries 33 min
33 minAI Dev 26 x SF | Carter Rabasa: File Systems Are the New Primitive for AI Agents
 28 min
28 minAI Dev 26 x SF | Melissa Herrera: Your Agents Should Be Durable
 31 min
31 minAI Dev 26 x SF | Vlad Luzin: Herding Cats—The Hidden Challenges of Multi-Agent Autonomy
 43 min
43 minAI Dev 26 x SF | Paige Bailey: What's New and What's Next in AI
Ask anything from this episode.
Save it, chat with it, and connect it to Claude or ChatGPT. Get cited answers from the actual content — and build your own knowledge base of every podcast and video you care about.
Get Started Free